Recently I was working on a capacity planning project and this reminded me about my learning’s from one of the capacity planning engagements during my previous role as a Server Virtualization Consultant. In this blog post I would like to share the learning’s about doing Capacity Planning using Standard Deviation. I had a task to do the capacity planning for eight ESXi 4.0 hosts where the client was interested to know the available capacity to add new workloads. In this task I didn’t have the privilege to use CapacityIQ or vCenter Operations Manager which automates the entire data gathering and analytics process. The performance data from the existing ESXi hosts were shared in an Excel where I had hourly CPU & Memory usage for 45 days. Trust me, this is not one of the engagements that I had enjoyed considering the amount of manual work that was required. While I was researching for the best possible approach my colleague Richard Raju suggested that we explore using Standard Deviation for this since all the data is in Excel and StdDev can be used easily in Excel. Alternatively I could also take 90th percentile of the max usage to determine the available capacity.
Though using 90th percentile of the maximum utilization is common, I wanted to explore using Standard Deviation. After understanding how it works, I used the same concept with more engagements.
Capacity Planning using Standard Deviation
Review the RAW data, this is the RAW data that I received from the client

Note that I received the hourly data for the following metrics:
- Processor Percent Used
- Processor Usage MHz
- Memory Percent Used
As a best practice I have capped the utilization at 80%, leaving aside 20% for spikes and failover resources in HA cluster. Hence I added the following fields:
Utilization capped at 80% = (80* Processor Percent Used)/100
CPU Capacity Available = 80- Processor Percent Used
NOTE: It’s not mandatory to cap the utilization at 80% however I have used this as best practice in this case to ensure that I am not overcommitting the resources.
Once you have collated all this information you can create a Pivot Table with the above values. All you have to do is select all the columns/rows and click on Insert > Pivot table from the file menu. You should now get a similar output.
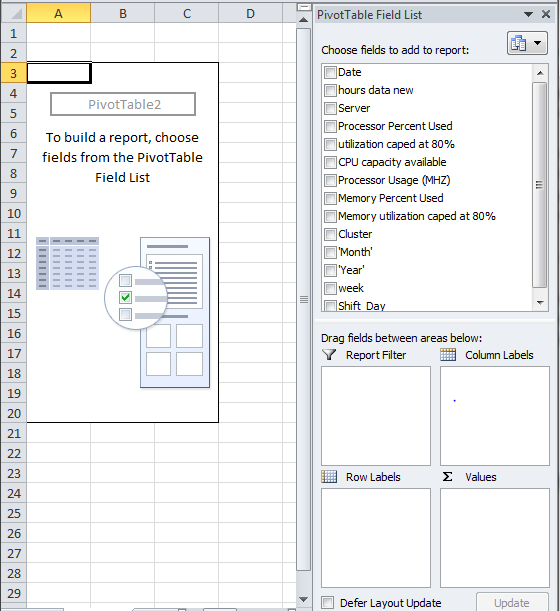
You now have to drag the values from the “Choose fields to add to report” to the “Drag fields between areas below”. In this example I will demonstrate how the Average, Minimum, Maximum & Standard Deviation for CPU was calculated. Similar approach can be used to calculate Memory Usage and then project the available capacity.
I have dragged the Shift_Day, Week, and Cluster fields in Report Filter so that I can pick and choose the data for different Servers during the weekdays for specific business hours and also for weekends. Note it’s important to cover these data points because generally the Servers may be utilized only during business hours and adding the data for after business hours may impact the overall utilization.
In the Row Labels, I will drag the Server so that I can get the utilization for all the servers.
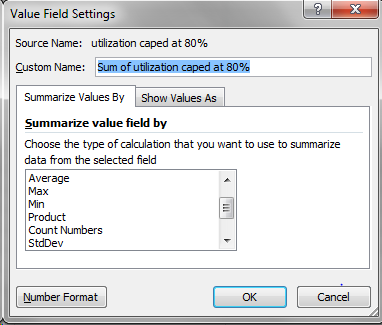
In Values section drag “CPU Utilization capped at 80%”. Note that by default the “SUM of CPU Utilization capped at 80%” is reported in the Values section. You would have to change this to Max, Min, Average and Stand Dev. To do this, you have to click on the dropdown option available on the sum of CPU Utilization capped at 80% and then click on click on Value Field Settings and then click on Average. Follow the same steps to select Min, Max & Std Dev. Here is the screenshot of the values that you need to add.
You should now have the following output for the CPU Utilization. With this we have found the number of standard deviations in the CPU Utilization. I will use this value while calculating the capacity.

Here you can see the number of standard deviations for the CPU utilization for Server-1 is 4.86. Similarly we can calculate the Memory Utilization capped at 80%.
Once you have the number of standard deviations, you can now calculate the Average CPU Usage based on Standard Deviation. To do this I have used the following

Let me explain the important fields
- CPU – Number of Sockets
- Cores – Number of Cores per Socket
- Speed – Speed of each core
- Total CPU (GHz) = (Number of Sockets) * (Number of Cores per Socket) * (Speed of each core)
- The Min, Max, Average Processor % Used is provided from the Pivot Table created in the above section.
- The “# of StdDev for Processor % Used” is also derived from the Pivot Table.
We now have to understand the number of standard deviation for maximum processor usage.
Number of Standard Deviation for Max = (Max Processor Percent Used - Average Processor Percent Used)/StdDev of Processor Percent Used
Since this value is greater than three I have calculated the CPU Usage based on 3x StdDev using the below formula
CPU Usage based on StdDev = Average Processor Percent Used + (StdDev of Processor Percent Used * 3)
Once the CPU Usage is available (in the above example the CPU Usage based on StdDev is 63.98%), I have calculated the Available Capacity in % using the following formulas
Minimum Available Capacity (%) = 80 – Max Processor % Used
Maximum Available Capacity (%) = 80 – CPU Usage based on 3x StdDev
The above values regarding Available Capacity is in percentage and it has to be converted to MHz or GHz to find how many more vCPUs can be added. To convert the Maximum & Minimum Available Capacity, I have used the following formual
Minimum Available Capacity = = (Total CPU GHz * Minimum Available Capacity)/100
Maximum Available Capacity = = (Total CPU GHz * Maximum Available Capacity)/100
The client requirement is now met because we know what is the available capacity on the servers and how much workload can be added. Interestingly our findings also matched with the output of CapacityIQ which we were able to run only after 2 months.
Please drop your comments if you have anything to add about this approach.